
GMM clustering using BERT embeddings and PCA reduction to 2 dimensions show the difficulty of the clustering task, as there is little variety in the clusters and they heavily overlap. We use co-variance type "full".
Ayaan Haque: ayaanzhaque@gmail.com
Viraaj Reddi: viraajreddi@gmail.com
Tyler Giallanza: tylerg@princeton.edu
* Authors contributed equally
This paper was accepted to 30th International Conference on Artificial Neural Networks (ICANN 2021) which will be held in September of 2021.
Early detection of suicidal ideation in depressed individuals can allow for adequate medical attention and support, which in many cases is life-saving. Recent NLP research focuses on classifying, from a given piece of text, if an individual is suicidal or clinically healthy. However, there have been no major attempts to differentiate between depression and suicidal ideation, which is an important clinical challenge. Due to the scarce availability of EHR data, suicide notes, or other similar verified sources, web query data has emerged as a promising alternative. Online sources, such as Reddit, allow for anonymity that prompts honest disclosure of symptoms, making it a plausible source even in a clinical setting. However, these online datasets also result in lower performance, which can be attributed to the inherent noise in web-scraped labels, which necessitates a noise-removal process. Thus, we propose SDCNL, a suicide versus depression classification method through a deep learning approach. We utilize online content from Reddit to train our algorithm, and to verify and correct noisy labels, we propose a novel unsupervised label correction method which, unlike previous work, does not require prior noise distribution information. Our extensive experimentation with multiple deep word embedding models and classifiers display the strong performance of the method in a new, challenging classification application.
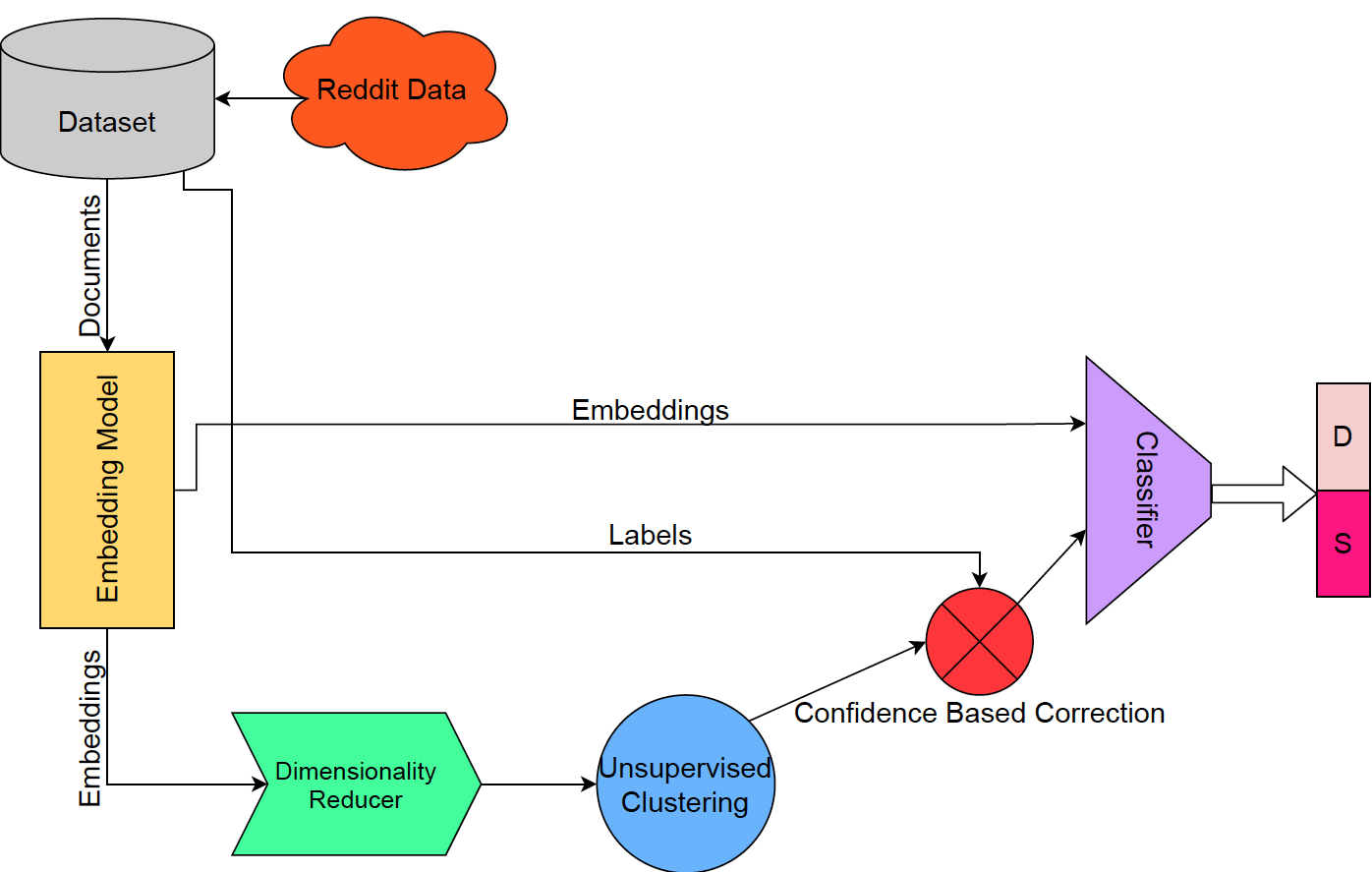
Using Reddit data poses the issue of noisy labels, or corrupted labels. In order to utilize large webscraped datasets, we use unsupervised clustering to perform confidence-based correction of the labels in the dataset.
GMM clustering using BERT embeddings and PCA reduction to 2 dimensions show the difficulty of the clustering task, as there is little variety in the clusters and they heavily overlap. We use co-variance type "full".
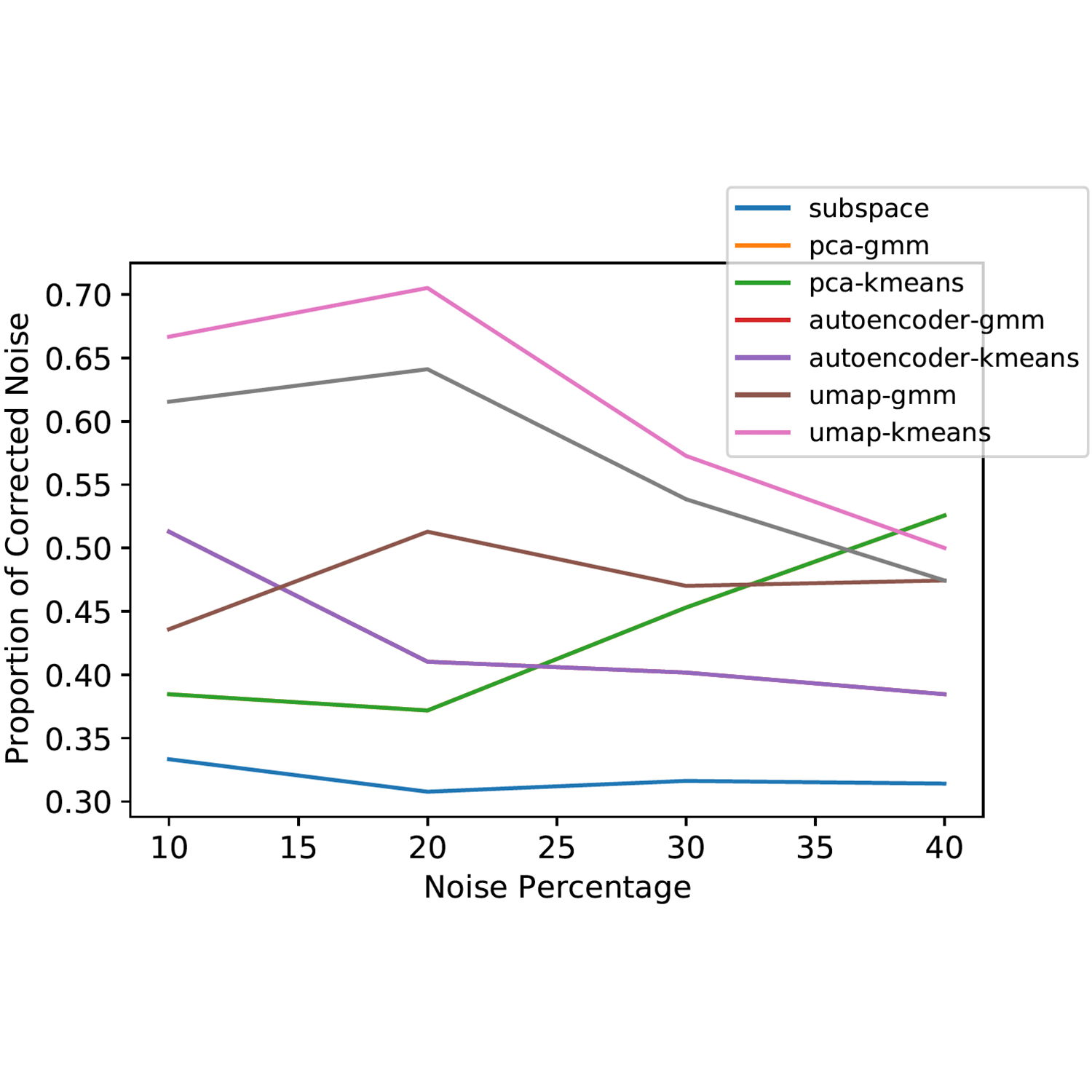
Correction rates of the label correction algorithms at different noise rates on the IMDB dataset. The left figure displays correction rates with uniform noise injections, and the right figure displays correction rates with class-weighted noise injections. For example, we split by 30%-10% or 25%-15%.
We use deep transformers and classifiers to perform suicide vs depression classification. After extensive experimentation, SDCNL achieves upwards of 95% accuracy, outperforming numerous other studies on a more difficult task.
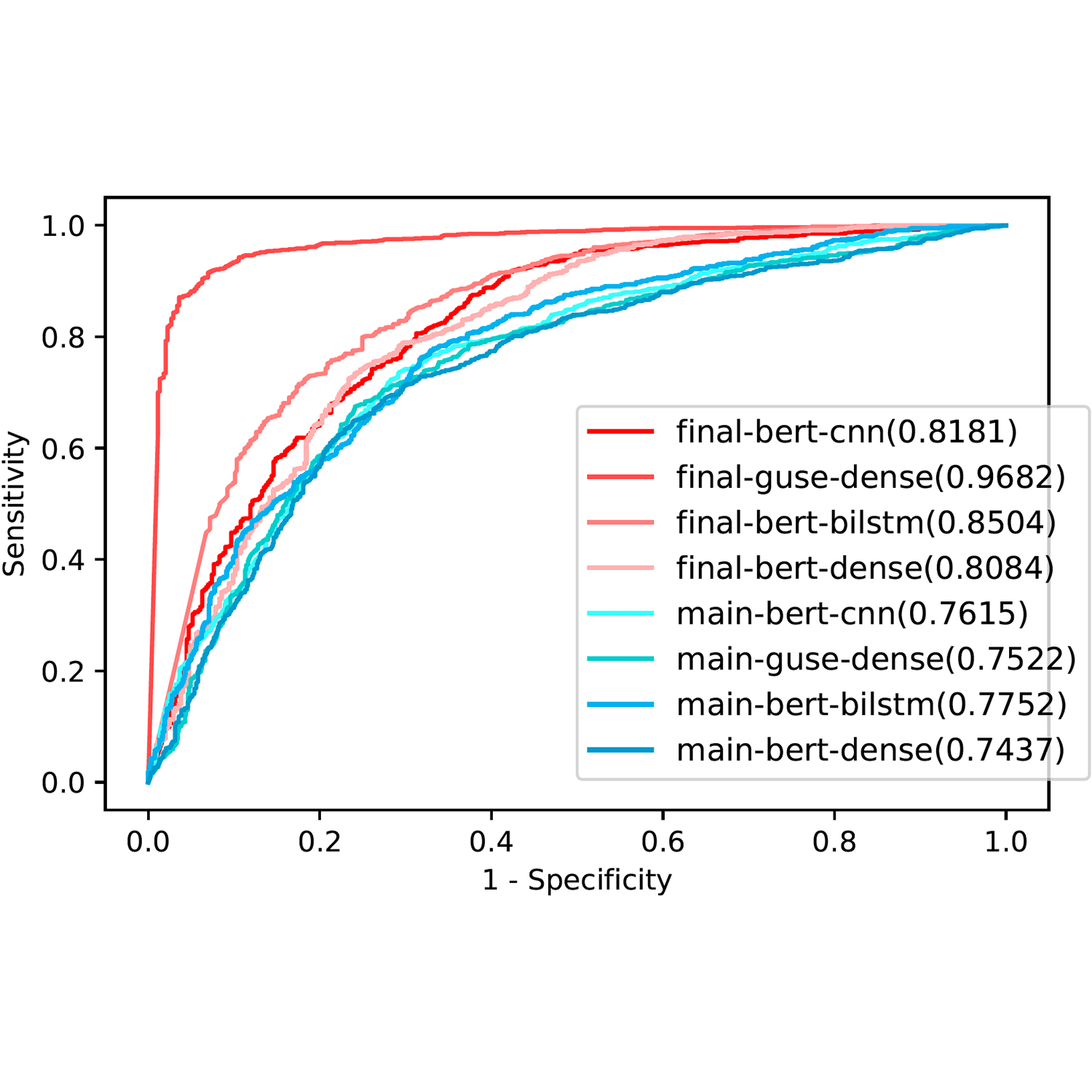
ROC curves of performance of top 4 models with label correction (red) against the same models without label correction (blue).
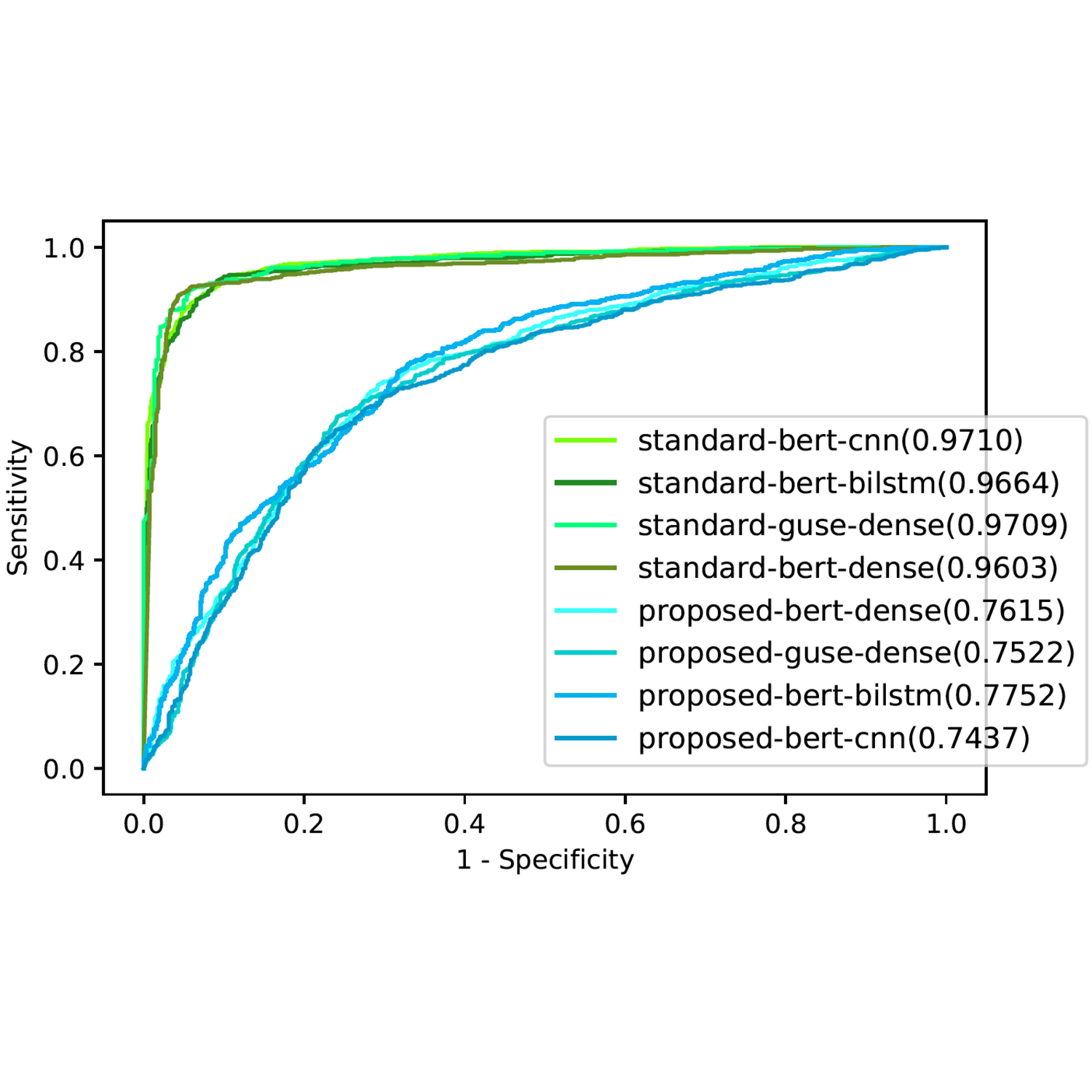
ROC curves of model performance from four best models on our task (proposed) against the conventional suicide vs healthy task (standard).
The applied setting of our system is to provide professionals with a supplementary tool for individual patient diagnosis, as opposed to solely being a screening method on social media platforms. SDCNL could be used by professional therapists as a "second opinion", friends and family as a preliminary screening for loved ones, or even on social media platforms to identify at-risk users. We contend that our method is applicable in a clinical setting given Reddit's propensity for honest user disclosure, especially considering the ability of our label correction method to remove substantial amounts of noise from the labels. As opposed to models trained on EHRs or suicide notes, which often include limited amounts of data, leveraging online content allows for the use of data-hungry deep learning models, which we prove can be quite effective.
@article{haque2021deep
title = {Deep Learning for Suicide and Depression Identification with Unsupervised Label Correction},
author = {Ayaan Haque and Viraaj Reddi and Tyler Giallanza},
year = {2021},
eprint = {2102.09427},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}